[서버-7] 블록 소켓과 논블록 소켓
#서버 프로그래밍블록 소켓과 논블록 소켓의 차이점 (논블록 소켓 중점으로)
블록 소켓
디스크를 읽거나 쓸 때 사용하는 read(), write() 함수는 호출 후 실행이 완료될 때까지 리턴하지 않는다.
같은 느낌으로 소켓을 이용할 때 send()와 receive()에서 리턴이 바로 되지 않고 완료될 때까지 기다린다면 블록 소켓 방식이라고 부른다.
다중 클라이언트를 처리할 때 블록 소켓 방식으로 서버를 구축한다면 멀티스레드 방식으로 소켓의 개수만큼 스레드를 가져야 된다. 단일 스레드로 구축했다가 하나의 소켓에서 블록이 발생하면 다른 소켓에 대한 응답이 늦어져 동시성을 제공하기 어렵기 때문이다.
블록 소켓의 한계점
그러나 만약 클라이언트 수가 굉장히 많다면 어떤가 여기서 블록 소켓의 한계점이 드러난다. 클라이언트의 수가 1000개라서 스레드도 1000개를 만들면 각 스레드가 호출하는 호출 스택이 1MB씩 총 1GB가 필요하다.
게다가 각 스레드에서 다른 스레드로 Context Switch도 빈번히 발생할텐데 이 오버헤드 역시 만만치 않다.
논블록 소켓
위의 한계를 극복할 수 있는 방안 중 하나가 논블록 소켓이다. 이를 이용하면 소켓 함수에서 블록이 발생하지 않는다.
논블록 소켓을 사용하는 방법은 크게 다음과 같다.
- 소켓을 논블록 소켓으로 전환한다.
- 논블록 소켓에 대해 평소처럼 송신, 수신, 연결과 관련된 함수를 호출한다.
- 논블록 소켓은 무조건 이 함수 호출에 대해 즉시 리턴한다. 리턴 값은
성공혹은would block둘 중 하나이다.
would block이란 블로킹이 걸렸어야 할 상황인데 블로킹이 걸리지 않았다는 의미이다.
논블록 소켓을 사용하는 코드를 보면 다음과 같다.
void NonBlockSocketOperation()
{
s = socket(TCP);
...;
s.connect(...);
// 논블록 소켓으로 변경
s.SetNonBlocking(true);
while (true)
{
// ➊
r = s.send(dest, data);
if (r = = EWOULDBLOCK)
{
// 블로킹 걸릴 상황이었다. 송신을 안 했다.
continue;
}
if (r = = OK)
{
// 보내기 성공에 대한 처리
}
else
{
// 보내기 실패에 대한 처리
}
// ➋
}
}먼저 무한 반복문이 눈에 띈다. 계속해서 반복하여(폴링) 처리가 잘 되었는지 확인한다. 이는 CPU의 부담으로 연결될 수 있다.
아래와 같이 단일 스레드에서 여러 개의 소켓을 처리할 수도 있다.
List<Socket> sockets;
void NonBlockSocketOperation()
{
while (true)
{
foreach(s in sockets)
{
// 논블록 수신 ➊
(result, data) = s.receive();
if (data.length > 0)
{
print(data);
}
else if (result != EWOULDBLOCK)
{
// 소켓 오류 처리를 한다.
}
}
// ➋
}
}역시나 찝찝한 부분은 무한 반복문이다. CPU의 부담이 생기기 쉬운 구조이다. 이를 해결하기 위한 방법은 아래와 같다.
- 여러 소켓 중 하나라도
would block이었던 상태에 변화가 일어나면 그 상황을 알려주는 함수 - 혹은 그것을 알려 주기 전까지는 블로킹 중이어서 CPU 사용량 폭주를 해결하는 함수
위 작업을 해주는 함수가 존재한다 select() 혹은 poll()이다.
List<Socket> sockets;
void NonBlockSocketOperation()
{
while (true)
{
// 100밀리초까지 대기 ➊
// 1개라도 I/O 처리를 할 수 있는 상태가 되면
// 그 전에라도 리턴
select(sockets, 100ms);
foreach(s in sockets)
{
// 논블록 수신 ➋
(result, data) = s.receive();
if (data.length > 0)
{
print(data);
}
else if (result != EWOULDBLOCK)
{
// 소켓 오류 처리를 한다.
}
}
}
}➊에서 select()를 호출한다. sockets에서 I/O 처리가 가능한 소켓이 하나라도 있을 경우 즉시 리턴한다. 그렇지 않으면 100밀리초까지 블로킹한다.
그 전에라도 조건을 만족하면 즉시 리턴한다.
select() 함수가 리턴한 후에 sockets의 각 소켓에 대한 논블록 I/O 처리 함수를 호출하면 된다. 아직 would block인 것도 있겠지만 최소한 하나는 would block이 아닌 다른 결과가 나올 것이다.
정리
논블록 소켓의 장점
- 스레드 블로킹이 없으므로 중도 취소 같은 통제가 가능하다
- 스레드 개수가 1개이거나 적어도 소켓을 여러 개 다룰 수 있다.
논블록 소켓의 단점
그러나 위에서 다루진 않았지만 단점도 역시 존재한다.
- 소켓 I/O 함수가 리턴한 코드가
would block인 경우 재시도 호출 낭비가 발생한다. - 소켓 I/O 함수를 호출할 때 입력하는 데이터 블록에 대한 복사 연산이 발생한다.
첫 번째 재시도 호출 낭비의 예로 다음의 경우가 있다.
UDP의 경우 송신 버퍼에 1바이트라도 있으면 I/O 가능이다. 그런데 보내려는 데이터가 5바이트인데 송신 버퍼 빈 공간이 1바이트라면 TCP와 다르게 would block이 발생한다.
TCP는 우선 1바이트라도 송신 버퍼에 집어 넣지만 UDP는 일부만 송신 버퍼에 넣는 것이 허락되지 않는다. I/O 가능이라 재시도 했는데 여전히 would block이다. 이 상태로라면 UDP는 send()를 못한 채 결국 CPU 낭비이다.
두 번째 복사 연산 발생 단점은 다음과 같다.
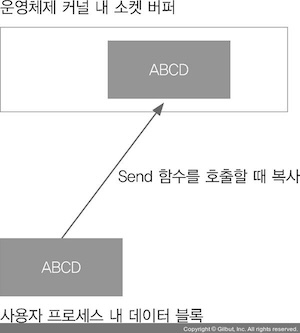 게임 서버 프로그래밍 교과서 - 배현직
소켓 송수신 함수에 들어가는 데이터 블록 인자를 성공적으로 실행하면 위와 같이 메모리 복사 연산이 발생한다.
메모리에 있는 내용을 소켓 버퍼로 복사하는데 RAM은 CPU 캐시 메모리보다 속도가 느린 부품이다. CPU 캐시 메모리에 내용이 이미 복사되어 있으면 데이터 액세스가 빠르지만 없다면 메인 메모리 RAM에 액세스 해야 되는데 속도가 느리다.
보통 RAM은 속도가 빠른 장치로 인식되지만 고성능 서버에서는 RAM의 액세스 속도를 무시할 수 없다.
게임 서버 프로그래밍 교과서 - 배현직
소켓 송수신 함수에 들어가는 데이터 블록 인자를 성공적으로 실행하면 위와 같이 메모리 복사 연산이 발생한다.
메모리에 있는 내용을 소켓 버퍼로 복사하는데 RAM은 CPU 캐시 메모리보다 속도가 느린 부품이다. CPU 캐시 메모리에 내용이 이미 복사되어 있으면 데이터 액세스가 빠르지만 없다면 메인 메모리 RAM에 액세스 해야 되는데 속도가 느리다.
보통 RAM은 속도가 빠른 장치로 인식되지만 고성능 서버에서는 RAM의 액세스 속도를 무시할 수 없다.
위의 논블록 소켓의 단점을 해결하기 위한 방식으로 Overlapped I/O 혹은 Asynchronous I/O 방식이 있다.